详解布隆过滤器并使用 Go 实现它
布隆过滤器用以判断某个元素是否在集合中,可以有效的解决缓存穿透。
Gmail 的问题
在正式接触布隆过滤器前,让我们先思考一下 Gmail 的一个问题:如何过滤垃圾邮件地址?我们很容易想到,建立一张数据表,将每个垃圾邮件地址记录进去,然后比对查询即可。这样做当然可以解决这个问题,但全球这种垃圾邮件地址有几十亿,假使一个 email 占据十六个字节,那么几十亿的 email 会占据相当可观的内存。那么,我们来尝试下另外一种方法,先建立一个“纸带”,这个纸带长度为一千,每个位置上只能保存0或者1,我们称这个纸带叫位图,位图默认每个位置上都是0,像这样:
然后我们通过如下方法来处理一个 email :
- 将 email 进行 hash 运算后得到十六进制结果;
- 将结果取模 1000 (取模就是整除1000得到的余数),结果是250;
- 然后将位图上第 250 位的 0 标记为 1。
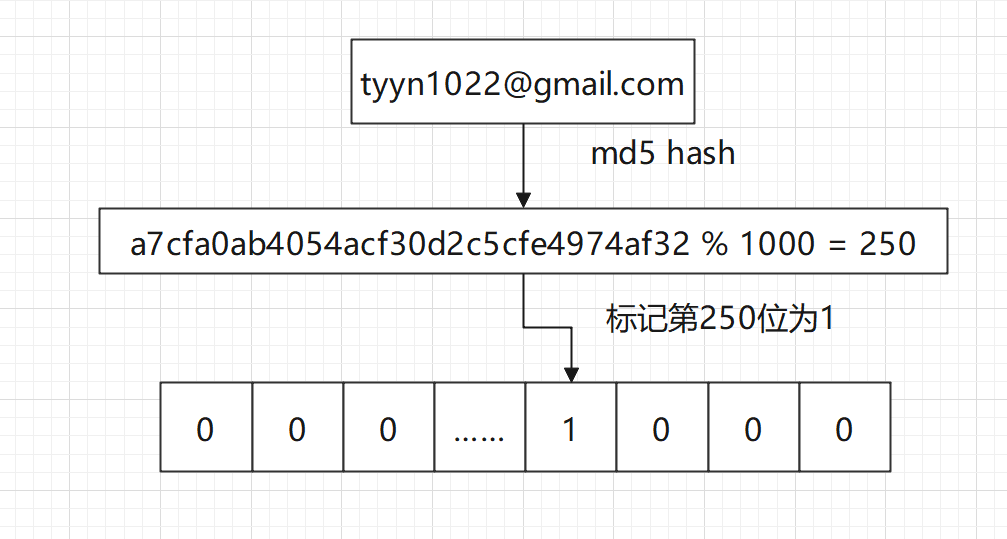
当在位图标记250位为1后,下次我们再检测 tyyn1022@gmail 这个邮箱是否是垃圾邮件时,只需要 hash 取模一次,然后判断对应位置上是否为1,就可以确定这个 email 是什么成分了。辣么,此时会带来一个新问题:由于位图上只有 1000 个,多个 email 极有可能指向位图上的同一个位置上,怎么解决呢?一种方式是增加位图的长度来降低误判率,但这不就是散列表了嘛,显然不可取。另外一种方式是可以对同一个 email 进行多种 hash 运算:
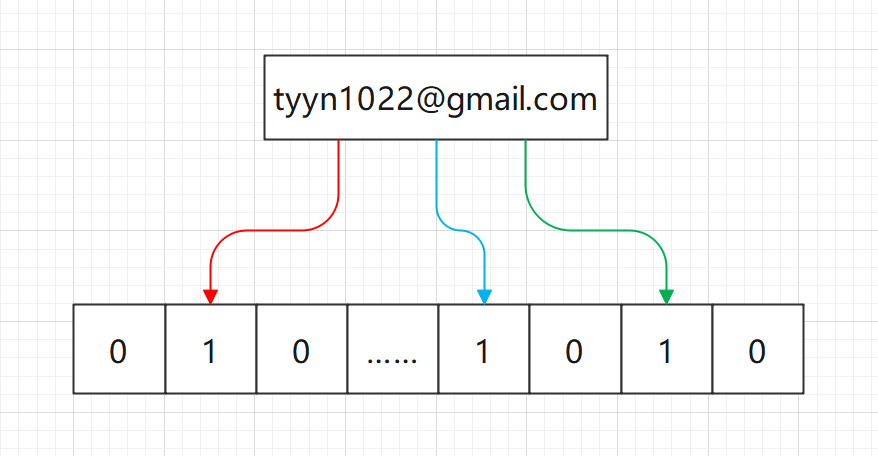
如图,我们对 email 进行三种不同的 hash 运算,只有当三种 hash 运算的结果在三个位置都是1的时候,才判定该元素存在。这种多次 hash 的结果记录在位图上的骚操作,有一个响当当的名字:布隆过滤器。有时候看到让人眼前一亮的奇思妙想,也不知道前辈们为什么这么聪明,ಠ_ಠ。
布隆过滤器的特点
从上文的分析中,我们可以看到布隆过滤器的几个显著优点:
- 节省空间,相对于把所有元素全部保存在集合中,布隆过滤器可节省太多了;
- 提高查询性能,不需要像集合那样线性查询,只需要查询计算结果的位置即可;
- hash 函数之间没有相互关系,可以由硬件实现并行计算,更进一步提高查询性能;
- 不存储原数据,对需要保密的场景具备优势。
布隆过滤器也存在一定的缺点:
- 误判率:布隆过滤器在查询时可能会出现误判,随着元素数量的增多,误判率会增大;
- 不支持删除操作:一旦元素被添加到布隆过滤器中,就无法删除,因为删除操作可能会影响到其他元素的判断结果;
- 布隆过滤器只能判断一个元素可能存在于集合中,但无法获取具体的元素值。
所以,你现在有没有理解这两句广为流传的话呢?
- 布隆过滤器说某个元素存在,那么不一定存在;
- 布隆过滤器说某个元素不存在,那么这个元素一定不存在。
使用 Go 实现一个简单的布隆过滤器
有兴趣的可以继续往下看哦!你也可以尝试使用别的编程语言实现它。
package main
import (
"fmt"
"hash/fnv"
)
type BloomFilter struct {
bitArray []bool
hashList []BloomFilterHash
}
// BloomFilterHash 布隆过滤器的hash
type BloomFilterHash func(s string) uint32
func NewBloomFilter(size uint32) *BloomFilter {
return &BloomFilter{
bitArray: make([]bool, size),
}
}
// RegisterHash 注册hash函数
func (b *BloomFilter) RegisterHash(h ...BloomFilterHash) {
b.hashList = append(b.hashList, h...)
}
// Add 添加一个元素
func (b *BloomFilter) Add(s string) {
bitLen := uint32(len(b.bitArray))
for _, v := range b.hashList {
index := v(s) % bitLen
b.bitArray[index] = true
}
}
// Exist 判断一个元素是否存在
func (b *BloomFilter) Exist(s string) bool {
var (
bitLen = uint32(len(b.bitArray))
hashLen = uint32(len(b.hashList))
count uint32 = 0
)
for _, v := range b.hashList {
index := v(s) % bitLen
if b.bitArray[index] {
count++
}
}
if hashLen == count {
return true
}
return false
}
// 使用New32a实现第一个hash
func hash1(s string) uint32 {
h := fnv.New32a()
h.Write([]byte(s))
return h.Sum32()
}
// 使用New32实现第一个hash
func hash2(s string) uint32 {
h := fnv.New32()
h.Write([]byte(s))
return h.Sum32()
}
func main() {
testStr := "tyyn1022@gmail.com"
bloom := NewBloomFilter(1 << 16)
bloom.RegisterHash(hash1, hash2)
// 添加元素
bloom.Add(testStr)
// 检测元素是否存在
fmt.Println(bloom.Exist(testStr))
fmt.Println(bloom.Exist(testStr + "not exist"))
}
本文目录