Go 并发编程 - Goroutine 基础 (一)
Goroutine 是 Golang 协程的实现。相比于其他语言,Goroutine 更加轻量,更加简单。Goroutine 是学习 Golang 必须掌握的知识。本文介绍 Goroutine 的基础知识,包含 基础语法使用和 Channel。
基础概念
进程与线程
进程是一次程序在操作系统执行的过程,需要消耗一定的CPU、时间、内存、IO等。每个进程都拥有着独立的内存空间和系统资源。进程之间的内存是不共享的。通常需要使用 IPC 机制进行数据传输。进程是直接挂在操作系统上运行的,是操作系统分配硬件资源的最小单位。
线程是进程的一个执行实体,一个进程可以包含若干个线程。线程共享进程的内存空间和系统资源。线程是 CPU 调度的最小单位。因为线程之间是共享内存的,所以它的创建、切换、销毁会比进程所消耗的系统资源更少。
举一个形象的例子:一个操作系统就相当于一支师级编制的军队作战,一个师会把手上的作战资源独立的分配各个团。而一个团级的编制就相当于一个进程,团级内部会根据具体的作战需求编制出若干的营连级,营连级会共享这些作战资源,它就相当于是计算机中的线程。
什么是协程
协程是一种更轻量的线程,被称为用户态线程。它不是由操作系统分配的,对于操作系统来说,协程是透明的。协程是程序员根据具体的业务需求创立出来的。一个线程可以跑多个协程。协程之间切换不会阻塞线程,而且非常的轻量,更容易实现并发程序。Golang 中使用 goroutine 来实现协程。
并发与并行
可以用一句话来形容:多线程程序运行在单核CPU上,称为并发;多线程程序运行在多核CPU上,称为并行。
Goroutine
Golang 中开启协程的语法非常简单,使用 Go 关键词即可:
func main() {
go hello()
fmt.Println("主线程结束")
}
func hello() {
fmt.Println("hello world")
}
// 结果
主线程结束程序打印结果并非是我们想象的先打印出 “hello world”,再打印出 “主线程结束”。这是因为协程是异步执行的,当协程还没有来得及打印,主线程就已经结束了。我们只需要在主线程中暂停一秒就可以打印出想要的结果。
func main() {
go hello()
time.Sleep(1 * time.Second) // 暂停一秒
fmt.Println("主线程结束")
}
// 结果
hello world
主线程结束这里的一次程序执行其实是执行了一个进程,只不过这个进程就只有一个线程。
在 Golang 中开启一个协程是非常方便的,但我们要知道并发编程充满了复杂性与危险性,需要小心翼翼的使用,以防出现了不可预料的问题。
编写一个简单的并发程序
用来检测各个站点是否能响应:
func main() {
start := time.Now()
apis := []string{
"https://management.azure.com",
"https://dev.azure.com",
"https://api.github.com",
"https://outlook.office.com/",
"https://api.somewhereintheinternet.com/",
"https://graph.microsoft.com",
}
for _, api := range apis {
_, err := http.Get(api)
if err != nil {
fmt.Printf("响应错误: %s\n", api)
continue
}
fmt.Printf("成功响应: %s\n", api)
}
elapsed := time.Since(start) // 用来记录当前进程运行所消耗的时间
fmt.Printf("主线程运行结束,消耗 %v 秒!\n", elapsed.Seconds())
}
// 结果
成功响应: https://management.azure.com
成功响应: https://dev.azure.com
成功响应: https://api.github.com
成功响应: https://outlook.office.com/
响应错误: https://api.somewhereintheinternet.com/
成功响应: https://graph.microsoft.com
主线程运行结束,消耗 5.4122892 秒!我们检测六个站点一个消耗了5秒的时间,假设现在需要对一百个站点进行检测,那么这个过程就会耗费大量的时间,这些时间都被消耗到了 http.Get(api) 这里。
在 http.get(api) 还没有获取到结果时,主线程会等待请求的响应,会阻塞在这里。这时候我们就可以使用协程来优化这段代码,将各个网络请求的检测变成异步执行,从而减少程序响应的总时间。
func main() {
...
for _, api := range apis {
go checkApi(api)
}
time.Sleep(3 * time.Second) // 等待三秒,不然主线程会瞬间结束,导致协程被杀死
...
}
func checkApi(api string) {
_, err := http.Get(api)
if err != nil {
fmt.Printf("响应错误: %s\n", api)
return
}
fmt.Printf("成功响应: %s\n", api)
}
// 结果
响应错误: https://api.somewhereintheinternet.com/
成功响应: https://api.github.com
成功响应: https://graph.microsoft.com
成功响应: https://management.azure.com
成功响应: https://dev.azure.com
成功响应: https://outlook.office.com/
主线程运行结束,消耗 3.0013905 秒!
可以看到,使用 goroutine 后,除去等待的三秒钟,程序的响应时间产生了质的变化。但美中不足的是,我们只能在原地傻傻的等待三秒。那么有没有一种方法可以感知协程的运行状态,当监听到协程运行结束时再优雅的关闭主线程呢?
sync.waitgroup
sync.waitgroup 可以完成我们的”优雅小目标“。 sync.waitgroup 是 goroutine 的一个“计数工具”,通常用来等待一组 goroutine 的执行完成。当我们需要监听协程是否运行完成就可以使用该工具。sync.waitgroup 提供了三种方法:
-
Add(n int):添加 n 个goroutine 到 WaitGroup 中,表示需要等待 n 个 goroutine 执行完成。
-
Done():每个 goroutine 执行完成时调用 Done 方法,表示该 goroutine 已完成执行,相当于把计数器 -1。
-
Wait():主线程调用 Wait 方法来等待所有 goroutine 执行完成,会阻塞到所有的 goroutine 执行完成。
我们来使用 sync.waitgroup 来优雅的结束程序:
package main
import (
"fmt"
"net/http"
"sync"
"time"
)
func main() {
var (
start = time.Now()
apis = []string{
"https://management.azure.com",
"https://dev.azure.com",
"https://api.github.com",
"https://outlook.office.com/",
"https://api.somewhereintheinternet.com/",
"https://graph.microsoft.com",
}
wg = sync.WaitGroup{} // 初始化WaitGroup
)
wg.Add(len(apis)) // 表示需要等待六个协程请求
for _, api := range apis {
go checkApi(api, &wg)
}
wg.Wait() // 阻塞主线程,等待 WaitGroup 归零后再继续
elapsed := time.Since(start) // 用来记录当前进程运行所消耗的时间
fmt.Printf("线程运行结束,消耗 %v 秒!\n", elapsed.Seconds())
}
func checkApi(api string, wg *sync.WaitGroup) {
defer wg.Done() // 标记当前协程执行完成,计数器-1
_, err := http.Get(api)
if err != nil {
fmt.Printf("响应错误: %s\n", api)
return
}
fmt.Printf("成功响应: %s\n", api)
}
// 结果
响应错误: https://api.somewhereintheinternet.com/
成功响应: https://api.github.com
成功响应: https://management.azure.com
成功响应: https://graph.microsoft.com
成功响应: https://dev.azure.com
成功响应: https://outlook.office.com/
线程运行结束,消耗 0.9718695 秒!
可以看到,我们优雅了监听了所有协程是否执行完毕,且大幅度缩短了程序运行时间。但同时我们的打印响应信息也是无序的了,这代表了我们的协程确确实实异步的请求了所有的站点。
Channel
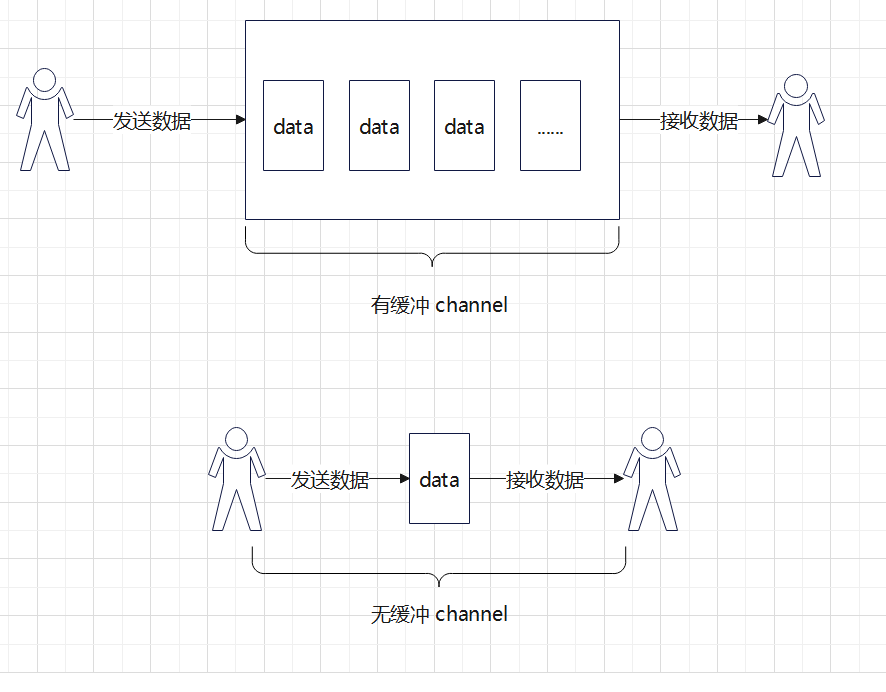
channel 也可以完成我们的”优雅小目标“。 channel 的中文名字被称为“通道”,是 goroutine 的通信机制。当需要将值从一个 goroutine 发送到另一个时,可以使用通道。Golang 的并发理念是:“通过通信共享内存,而不是通过共享内存通信”。channel 是并发编程中的一个重要概念,遵循着数据先进先出,后进后出的原则。
声明 Channel
声明通道需要使用内置的 make() 函数:
ch := make(chan <type>) // type 代表数据类型,如 string、intChannel 发送数据和接收数据
创建好 channle 后可以使用 <- 来发送/接受数据:
func main() {
ch := make(chan int)
go func() {
ch <- 1 // 发送
}()
a := <-ch // 接收
fmt.Println(a)
close(ch) // 关闭通道
}
// 结果
1每个发送数据都必须有正确的接受方式,否则会编译错误。编译错误比误用 channel 更好!
接收 channel 中的发来的数据时, a := <-ch 这里是处于阻塞状态的。我们可以利用这点来监听协程是否执行完成,还是上文的例子,但这次我们不使用 sync.waitgroup:
func main() {
var (
start = time.Now()
apis = []string{
"https://management.azure.com",
"https://dev.azure.com",
"https://api.github.com",
"https://outlook.office.com/",
"https://api.somewhereintheinternet.com/",
"https://graph.microsoft.com",
}
ch = make(chan string)
)
for _, api := range apis {
go checkApi(api, ch)
}
// 因为我们一共有六个请求,所以我们要接收六次
for i := 0; i < 6; i++ {
fmt.Println(<-ch)
}
elapsed := time.Since(start) // 用来记录当前进程运行所消耗的时间
fmt.Printf("线程运行结束,消耗 %v 秒!\n", elapsed.Seconds())
}
func checkApi(api string, ch chan string) {
_, err := http.Get(api)
if err != nil {
ch <- fmt.Sprintf("响应错误: %s", api)
return
}
ch <- fmt.Sprintf("成功响应: %s", api)
}
// 结果
成功响应: https://api.github.com
成功响应: https://management.azure.com
成功响应: https://graph.microsoft.com
成功响应: https://outlook.office.com/
成功响应: https://dev.azure.com
线程运行结束,消耗 0.9013927 秒!可以看到,我们利用通道接收数据的阻塞特性,达到了和使用 sync.waitgroup 一样的效果。
有缓冲 Channel
默认情况下,我们创建的 channel 是无缓冲的,意味着有接收数据,就一定要有对应的发送数据,否则就会永久阻塞程序。有缓冲的 channel 则可以避免这种限制。创建一个有缓冲的 channel:
ch := make(chan <type>, <num>) // num 代表有缓冲通道的大小有缓冲 channel 有点类似与队列,它不限制发送数据和接收数据,实现了接发 channel 的解耦。每次向 channel 中发送数据不用管有没有接收方,直接放入这个“队列”中。当有接收方从队列中取走数据时,就会从“队列”中删除这个值。当 channel 满时,发送数据会被阻塞,直到 channel 有空;当 channel 为空时,接收数据会被阻塞,直到 channel 有数据过来。
func main() {
ch := make(chan int, 3)
fmt.Printf("当前通道长度:%d\n", len(ch))
send(ch, 1)
send(ch, 2)
send(ch, 3)
fmt.Println("所有数据已经已经放入通道")
fmt.Printf("当前通道长度:%d\n", len(ch))
for i := 0; i < 3; i++ {
fmt.Println(<-ch)
}
fmt.Println("主线程结束")
}
// 结果
当前通道长度:0
所有数据已经已经放入通道
当前通道长度:3
1
2
3
主线程结束
这里并没有什么不同的操作,程序也在正常运行,但我们把通道大小改成比 3 更小时,编译就会出错,提示 fatal error: all goroutines are asleep - deadlock!这是因为我们在主线程中连续的执行send,最终超出了通道的限制。
func main() {
ch := make(chan int, 2) // 把通道改小
...
}
// 结果
当前通道长度:0
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.send(...)
E:/project/gotest/main.go:8
main.main()
E:/project/gotest/main.go:16 +0xfe
尝试使用协程来运行 send 函数:
func main() {
...
go send(ch, 1)
go send(ch, 2)
go send(ch, 3)
...
}
// 结果
当前通道长度:0
所有数据已经已经放入通道
当前通道长度:2
1
2
3
主线程结束channel 与 goroutine 有着千丝万缕的关系,在使用 channel 时一定要使用 goroutine。
Channel 方向
channel 有一个很有意思的功能,当通道作为函数的参数时,可以限制该通道是发送数据还是接收数据。当程序变的复杂后,这可以有效的记住每个通道的意图。一个简单的例子:
func send(ch chan<- string, message string) {
fmt.Printf("发送: %#v\n", message)
ch <- message
}
func read(ch <-chan string) {
fmt.Printf("接收: %#v\n", <-ch)
}
func main() {
ch := make(chan string, 1)
send(ch, "Hello World!")
read(ch)
}
// 结果
发送: "Hello World!"
接收: "Hello World!"
当错误使用通道时,编译会不通过:
# command-line-arguments
.\main.go:11:32: invalid operation: cannot receive from send-only channel ch (variable of type chan<- string)
多路复用
什么是多路复用
在实际的业务场景中,有时候需要根据不同的数据来处理不同的结果。举一个白话例子:
例如现在你有一个物流中心,这个物流中心具备一个这样的功能:从青岛、北海、舟山等城市接收海鲜,从朔州、大同等城市接受煤矿,从广州、苏州等城市接受制造业产出的生活用品。接收到这些物资后,根据物资种类发送到各个需要这些物资的地方,比如海鲜发往成渝做火锅,煤矿发往长三角发电,生活用品发往陕甘供生活使用。
Golang 提供 select 关键词来实现多路复用, select 就类似于这个物流中心,它用来接收多个 channel 中的数据,并做出不同的处理。select 的语法类似与 switch,都具备 case 和 default 但是 select 只适用于 channel。
func seafood(ch chan<- string) {
time.Sleep(2 * time.Second)
ch <- "海鲜已经送达"
}
func coal(ch chan<- string) {
time.Sleep(5 * time.Second)
ch <- "煤矿已经送达"
}
func goods(ch chan<- string) {
time.Sleep(8 * time.Second)
ch <- "生活用品已经送达"
}
func main() {
var (
text string
seafoodCh = make(chan string)
coalCh = make(chan string)
goodsCh = make(chan string)
tick = time.NewTicker(1 * time.Second)
)
go seafood(seafoodCh)
go coal(coalCh)
go goods(goodsCh)
for _ = range tick.C {
select {
case text = <-seafoodCh:
fmt.Println(text)
case text = <-coalCh:
fmt.Println(text)
case <-goodsCh:
fmt.Println("检测到有生活用品,但是不做处理")
default:
fmt.Println("什么都没来")
}
}
}
// 结果
什么都没来
海鲜已经送达
什么都没来
什么都没来
煤矿已经送达
检测到有生活用品,但是不做处理
什么都没来
什么都没来
什么都没来select 在运行时,如果所有 case 都不满足,就会选择 default 执行,如果没有 default ,select 会一直阻塞等待,直到至少有一个 case 满足被执行。如果同时有多个 case 被满足,则 select 会随机选择一个执行。
使用多路复用来实现 channel 超时
Golang 没有直接提供 channel 的超时机制,但是我们可以使用多路复用来实现:
func goods(ch chan<- string) {
time.Sleep(8 * time.Second)
ch <- "生活用品已经送达"
}
func main() {
var (
goodsCh = make(chan string)
)
go goods(goodsCh)
fmt.Println("开始等待")
select {
case <-goodsCh:
fmt.Println("生活用品送到了")
case t := <-time.After(3 * time.Second): // 三秒后 channel 发出当前时间
fmt.Println("没有等到生活用品")
fmt.Println(t.Format("2006-01-02 15:04:05"))
break
}
fmt.Println("主线程运行结束")
}
// 结果
开始等待
没有等到生活用品
2023-04-08 14:51:36
主线程运行结束
本系列文章:
本文目录